Security reference architecture for a serverless application

Serverless computing can help organizations reduce the operational overhead while delivering highly scalable and reliable services to the customers in a cost effective manner. But does using these serverless services also reduce the burden of security implementation? Simple answer is yes, since there is no server for the customers to manage, the security responsibilities that come with it are naturally reduced. Keep in mind that Serverless does not mean no servers, it means no responsibility for you to manage the servers yourself as your cloud provider would do the heavy lifting for you.
Then why really bother with this article about serverless security when it’s majorly taken care of by the cloud provider. One obvious reason is that not everything is managed by your provider, you as a customer still have some security responsibilities. And second, as an analogy, just because you have bought a yearly pest control treatment plan for your house, it does not mean that you would leave food all over the place, right? Meaning you would still need to follow best practices to reduce risk on your system. This article is just about that — helping you reduce your risk for a serverless application.
I will take the example of a demo serverless application and walk through what controls I have put in place to reduce the risk in it and what options you should be aware of as you are building your own serverless application.
Demo Application
It’s worth pointing out that there can be a number of application architectures possible with serverless computing today. Some of the common ones which are also illustrated in Serverless Applications Lens — AWS Well-Architected Framework are RESTful microservices, Alexa skills, Mobile Backend, Stream processing and Web Application.
I have created a demo serverless application to use as reference for this article — demo vulnerability management system app which securely exposes REST APIs with AWS services— API Gateway, Lambda, DynamoDB and S3. The example code is for AWS but the same concepts can be extended to any other public cloud environment.
In this simple example, a serverless application processes, stores and serves vulnerability data to its customers:
- Vulnerability scanner services like Nessus send a POST request with vulnerability data to the Route53 domain name which aliases to the API Gateway custom domain name
- API Gateway triggers POST Lambda function which processes and stores the data into DynamoDB
- Customers of the vulnerability data send a GET request with their org id as parameter to the Route53 domain name
- API Gateway triggers GET Lambda function which fetches the data for that org id from DynamoDB table and returns to the customer

Let’s now take a look at the security controls that are integrated with this demo app and if you want to deploy this demo app into your own AWS environment, take a look at the detailed instructions at — How to deploy this code in your own environment
Security Integrations
Authentication
IAM 1.1 Only specific customers are allowed to access the REST APIs
- In the demo application, authentication is enabled via digital certificates using mutual TLS (mTLS). A root CA certificate is configured as part of API Gateway in order to authenticate client certificates. This is a good option if you have clients coming from a different cloud environment (cross-cloud traffic) or even on-premises. Some best practices around using this setup for production — client/server certificates must be short-lived so automatically creating and supplying it to all parties is critical from an operational standpoint. Also, private keys must be stored in a secure storage like Vault.

Relevant documentation → AWS documentation to enable mTLS with API Gateway
- If you have clients using the cloud provider’s identity e.g. an EC2 instance with an attached IAM role, then an easy option to authenticate is via cloud service provider’s native IAM system.
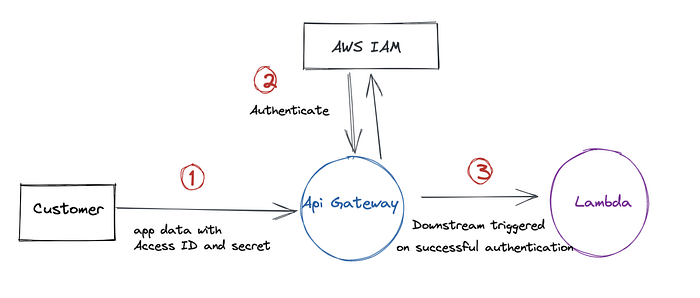
Relevant documentation → AWS documentation to enable IAM auth with API Gateway
- Authentication is also possible via OAuth Client Credentials Flow where the client authenticates with an authorization server using client credentials, gets an access token, and then calls the API Gateway with the access token.This would also be useful in cases were API customers may need to access the API over a Web UI:
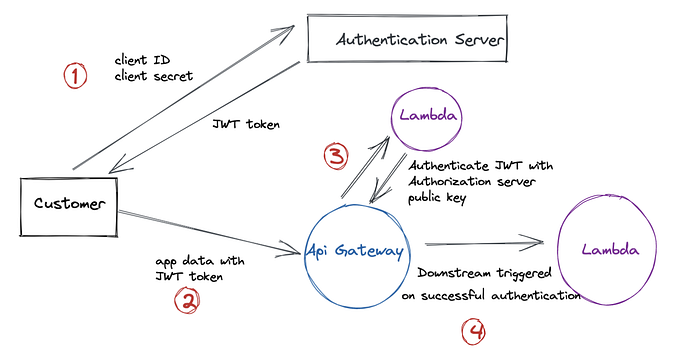
Relevant documentation →AWS documentation to enable API Gateway authentication using AWS Cognito
Authorization
IAM 1.2 Authenticated customers are only allowed to access specific resources. E.g — [Customer A can only GET data for Org 1, 2], [Customer B can only GET data for Org 3, 4], and [Only Admin A can POST new data]
- In the demo app, after mTLS authentication is successful, authorization happens via Lambda functions that validate if the OU (Organization Unit) in the certificate is authorized to perform the specific API method on the specific resource. This mapping is made accessible to the Lambda function via a DynamoDB table.
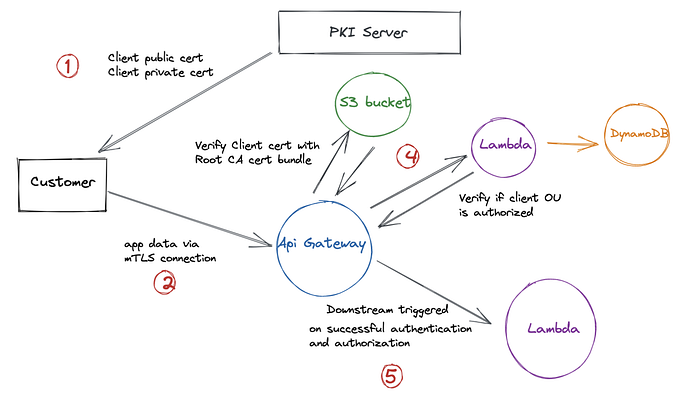
For OAuth flows, authorization is possible using client ID which is part of the JWT token or custom scopes
Infrastructure Least privilege
IAM 1.3 Serverless cloud resources have the least amount of permissions to perform their task and no more. Ergo, in cases of unwanted abuse of these resources, the blast radius is minimal.
Below are some of the examples of least privilege from the demo app:
- API Gateway is only allowed to invoke the specific downstream Lambda functions and the authorizer Lambda functions by assigning the following IAM policy Terraform resource to the API Gateway IAM role:
- The AWS IAM role for the Lambda function to respond to the GET API only has permissions — “dynamodb:GetItem” and “dynamodb:Query” on the specific DynamoDB table:
The AWS IAM role for the Lambda function to respond to the POST API only has permissions — “dynamodb:GetItem” and "dynamodb:PutItem" on the specific DynamoDB table:
Network Security
NS 1.1 API Customers are only able to access the REST APIs from specific network locations (ip addresses)
- In the demo application, the endpoint is public but it is restricted to be only accessed from my laptop ip address using resource policy on the API Gateway as shown below:
- An alternative to above would be use AWS WAF for IP filtering:
AWS documentation for creating IP filtering with WAF
- Also, you don’t need to expose API Gateway to public, there is an option with AWS to only create a private API Gateway endpoint. You may use AWS private link to connect to a private API Gateway endpoint from another AWS account.
NS 1.2 Encryption in transit with TLS is enabled on the API endpoint and only secure TLS protocol and cipher version is used
- With AWS API Gateway, you can choose a minimum Transport Layer Security (TLS) protocol version to be enforced for your Amazon API Gateway custom domain by setting a security policy. A security policy determines two things: 1) The minimum TLS version that API Gateway uses to communicate with API clients. 2) The cipher that API Gateway uses to encrypt the content that it returns to API clients
NS 1.3 The default API endpoint is disabled so that the mTLS controls on the custom domain are not bypassed by using the default domain
- For AWS API Gateway — https://docs.aws.amazon.com/apigateway/latest/developerguide/rest-api-disable-default-endpoint.html.
NS 1.4 Serverless cloud backend resources are not directly accessible by public urls or public cloud accounts. Cloud configuration mistakes like making a S3 bucket public can inadvertently expose the backend data of serverless apps
- For AWS, some of the resources where this capability exists and should be watched out for are very well explained in this open-source Git repo — AWS Exposable Resources
NS 1.5 For inter-communication between services, if not configured otherwise, the traffic is routed via public Internet, which seems like an unnecessary risk as these services, in most probability, are internal to your design. In such cases and as applicable with each cloud provider, it is advisable to use private endpoints so that traffic to serverless services be kept on cloud service provider’s backbone network rather than Internet at large. Endpoint policy is set up to only allow network access to a specific resource via the private endpoint
- In the demo app, VPC private endpoints are used for accessing S3 and DynamoDB. Lambda functions are connected to the VPC with a security group in order to access S3 and DynamoDB with a private VPC endpoint.
- VPC Endpoint policy is set up to only allow network access to a specific resource via the private endpoint.
Code Security Hygiene
CSH 1.1 Input is the most dangerous component of any code from a security perspective as each input field is a potential security vector that an attacker can leverage, and so care is taken before ingesting, processing or forwarding it to any third-party
- In the demo app, API Gateway is used for validation of request body and request parameter by configuring it in the openapi.yaml file:
- Request body passthrough is specifically set to
NEVERwhich is needed in cases where the request body payload cannot be validated, so that unsupported content types fail with 415 “Unsupported Media Type” response. - To prevent code vulnerabilities flowing to downstream systems, proper encoding is performed on all output. E.g. by doing
return json.dumps(output)prevents JSON injection attacks in downstream
CSH 1.2 API endpoints have API throttling limits so that the API is not overwhelmed with too many requests and does not become non-functional in the event of a denial of service attack
- AWS enables some default throttling limits for API Gateway so if that works for your design, you might not have to do this yourself.
- To set throttling limits for each of your API methods, you may create a Usage Plan
CSH 1.3 API endpoints have proper error handling with a duo objective — to store details logs internally for debugging by admins and to not reveal internal design/application details in the output to the customer. Also, it’s common sense, but execution of the program stops when an error occurs
CSH 1.4 Even Serverless applications are susceptible to database injection attacks and care is taken while implementing the queries that are run against the serverless databases like DynamoDB
- See example of how DynamoDB injection can work →NoSQL Injection: DynamoDB
- The demo app uses boto3 Dynamodb APIs to query the database and does not create dynamic queries by concatenating input strings.
CSH 1.5 Lambda function code must be treated like any other code in the organization i.e. it must be built via organizational CICD pipelines that have integrated static code analysis, dynamic analysis and third-party vulnerability scanning (e.g. using Snyk)
The above are some of the basics of code security hygiene but for production-grade applications, it is advisable to make sure your application code goes through proper pentesting procedures
Data Protection
DP 1.1 In order to prevent exposure of data stored on public cloud via physical access to disks, all data stored on the public cloud is encrypted with a secure symmetric algorithm like AES-256. Depending on the degree of security compliance required, data is either encrypted by customer supplied key (CSEK), or customer managed key (CMEK) or cloud provider managed key. The options you have also depend on the type of cloud service you are interacting with.
DP 1.2 For customer-management of the cloud provider encryption key, be mindful of the following taking the examples of AWS KMS service:
- In the demo app, for the centralized management of key access policies, AWS IAM is enabled to help control access of the CMK. This is done by assigning key permissions to the root AWS user —
arn:aws:iam::${aws:PrincipalAccount}:root}. Assigning kms:* to the above AWS user is “not secure” as it allows any IAM role in the same account with proper IAM permissions to perform sensitive key admin activities. Therefore, the KMS policy below specifically DENIES sensitive privileges like key deletion and only allows these sensitive actions to be done by select few IAM roles:
- Automatic key rotation is enabled for the CMK based on the organizational key rotation policy
DP 1.3 Data stored on cloud which is critical to the functioning of the organization and its customers is backed up for the time period (RTO and RPO) as defined in the organizational policy. The backup snapshots are also be copied to a different geographical region to plan for cloud provider region outages
- AWS Regional outages are becoming far common than you might expect, so its wise to be prepared with a backup plan — Data center power loss brings down AWS services, in another East Coast cloud outage
- AWS offers a centralized service to manage backup of multiple AWS services — AWS Backup
Logging
LO 1.1 Authentication and Authorization logs are stored by the Lambda function in CloudWatch and include details like user id, timestamp, resource, access failure reason, etc. that can help in forensic investigation later
- Below is an example of how Authorization logging can be achieved with Python:
LO 1.2 Cloud provider activity logs which provide details on who ran which api on what resource are stored in S3 bucket. These logs are useful for forensic investigations to create an event sequence
- For AWS, CloudTrail provides the activity logs but be careful of the default configuration as it does not log all data access events. Example, by default CloudTrail would log S3 Bucket-level calls which include events like
CreateBucket,DeleteBucket,PutBucketLifeCycle,PutBucketPolicy, etc, but it does not log object-level Amazon S3 actions like GetObject, PutObject, DeleteObject, etc. You can specifically enable data access logging for Lambda, S3 and DynamoDB when you are creating the CloudTrail using the event_selector data_source:
- Also depending on which AWS services you might be using, you will need to enable data access logs for those services on a per-resource basis. AWS documentation for some services like API Gateway, NLB and Cloudfront are linked below:
Access logs for your Network Load Balancer
LO 1.3 Networking logs provide ingress/egress ip address, port and protocol which can be used to track lateral movement from a particular compromised host.
- These are enabled via VPC flow logs in AWS
LO 1.4 All the logs stored are retained as per your organizational data retention policy based on regulatory compliance. Therefore it’s easier to store all logs in a central location like S3 and enforce retention and backup standards on this single location
LO 1.5 Preventative IAM policies explicitly deny the deletion of any of these log files. In AWS, you can do this by creating SCP to prevent users from deleting a particular S3 bucket, cloudwatch log or Glacier vault. You may also do this by creating Permission boundaries around IAM roles.
Concluding Notes
In my previous article, I talked about how Security engineers can provide valuable guidance to developers by creating simple, relatable and adoptable Reference Architectures — Uncomplicate Security for developers using Reference Architectures. In this article, I used the example of a demo serverless application and demonstrated the integration of security controls to reduce the risk of this application. I hope I was able to strengthen my case to the security engineers with regard to the efficacy of reference architectures in demonstrating secure patterns. For the developers reading this, I hope the demo app and the security discussion here will be of help to you in integrating security best practices early on in your serverless journey. Thank you for reading!
References
- Secure Serverless Demo App
- Serverless Applications Lens — AWS Well-Architected Framework
- AWS Exposable Resources
- Uncomplicate Security for developers using Reference Architectures
- AWS How-to guides:
- AWS documentation to enable mTLS with API Gateway
- AWS documentation to enable IAM auth with API Gateway
- AWS documentation to enable API Gateway authentication using AWS Cognito
- AWS documentation for creating IP filtering with WAF
- Disable default endpoint
- create a Usage Plan
- AWS Backup
- API Gateway Logs
- Access logs for your Network Load Balancer
- CloudFront access logs
- VPC flow logs in AWS
